
It’s the end of this blog as we know it – and I feel fine
The End of an Era .. kind of
For a blog that gets very little love from me, I’m often surprised that it still gets any traffic. If you found some old content here that you like, and would like to read more stuff like it, then you’ll probably find it in one of two places.
The first will be on the new netapp communities site where I’ll put all my NetApp focussed (and by association, most of my storage technology related) blog posts, I’m currently waiting for a direct URL to be created, and when it is, I’ll update this post with the URL once I have it in a few days
–UPDATE–
There isn’t a specific section where all my blogs appear by themselves, but the blogs will appear in the technology section of the netapp blogs along with stuff from other netappians … You can get straight to it from here -> http://community.netapp.com/t5/Technology/bg-p/technology
All the other NetApp related stuff (including my blog posts and comments on questions) can be found on my profile page http://community.netapp.com/t5/user/viewprofilepage/user-id/9283
The second place to find my content is on ……
crankbird.com
That will focus on the non-netapp stuff that I find interesting and will be much more regular with usually much shorter posts which I hope you’ll find interesting. If you like the way I write, I’d really appreciate it if you’d come check it out and make some comments (unless of course your URL is cheapviagratablets/shoppingcart?-“drop table students -“)
For those of you who read my blogs and come back here looking for more of the same, thank you, I’ll try to give you something better in the future.
John “Ricky” Martin – aka @life_no_borders, aka @JohnMartinIT aka @crankbird
NetApp at Cisco Live : Another look into the future
 It’s no secret that Cisco has been investing a LOT of resources into cloud, and from those investments, we’ve recently seen them release a corresponding amount of fascinating new technology that I think will change the IT landscape in some really big ways. For that reason, I think this year’s Cisco Live in Melbourne is going to have a lot of relevance to a broad cross section of the IT community, from application developers, all the way down to storage guys like us.
It’s no secret that Cisco has been investing a LOT of resources into cloud, and from those investments, we’ve recently seen them release a corresponding amount of fascinating new technology that I think will change the IT landscape in some really big ways. For that reason, I think this year’s Cisco Live in Melbourne is going to have a lot of relevance to a broad cross section of the IT community, from application developers, all the way down to storage guys like us.
For that reason, I’m really pleased to be presenting a Cisco partner case study along with Anuj Aggarwal who is the Technical account manager on the Cisco Alliance team for NetApp. Most of you wont have met Anuj, but if you’ve got the time, you should take the time to get to know him while he’s down here. Anuj knows more about network security, and the joint work NetApp and Cisco has been doing on hybrid cloud than anyone else I know, and this makes him a very interesting person to spend some time with, especially if you need to know more about the future of networking and storage in an increasingly cloudy IT environment.
I’m excited by this year’s presentation, because it expands on, and in many ways completes a lot of the work Cisco and NetApp have been doing since NetApp’s first appearance at Cisco Live in Melbourne in 2010 as a platinum sponsor, where we presented to a select few on SMT, or more formally Secure Multi-Tenancy.
Why private cloud needs an undo-key
A business mentor of mine once told me there are only four rational reasons why a company invests its capital, and those reasons are to improve revenue, decrease costs, reduce risk or improve agility. I asked if agility really deserved its own category, and he answered with a quote from Charles Darwin: –
“It is not the strongest of the species that survives, nor the most intelligent that survives. It is the one that is the most adaptable to change”

Undo from Java Swing Code-Project – Original Creator Edson Heng
He continued that improving revenue is actually almost arguable, because it’s the one thing over which the company has the least control, and that in a fast changing business environment, you’d be better off investing in agility so you can take advantage of uncertainty.
I was reminded of this recently because it’s been a little over ten years since Nick Carr wrote an article in the Harvard Business Review stating the IT doesn’t matter. I opened with this during NetApp’s recent Elevate conferences in Adelaide and Perth, and pointed out that IT that doesn’t improve top line revenue or a company’s agility is a recipe for a focus on nothing more than cost and risk reductions. I was surprised that my comment still provoked a pretty defensive result in some IT professionals.
As I talked about how IT infrastructure teams could learn a lot from agile software development methodologies, and that a datacenter built on software defined infrastructure would allow this, it struck me what was causing this defensive posturing. Risk management was THE key issue that had to be addressed before any of this could happen. To be sure, costs are important, but without a way of dealing with risk effectively, none of this agile, software defined, cloud nirvana was ever going to happen, or certainly not within the timeframes anyone outside of IT was going to tolerate.
This insight was particularly relevant to me because in IT, vendors talk a lot about private cloud to our customers. We talk about accelerating journeys, we talk about how it’s your cloud, we talk about the benefits and we publish case studies. At the same time our product organizations spend increasingly large amounts of their development time and resources on delivering technology to create service catalogs, analytics capabilities and automation and self-service frameworks.
Internally, and between ourselves in the breaks between presentations at events and conferences, many of us wonder why, despite the clear business benefits and available technology, the adoption rate is much slower than we would have expected, and many companies business units are leapfrogging their IT departments internal cloud developments to go directly to large public cloud offerings.
It wasn’t until I got home and I heard my wife say “That’s awesome, they’re teaching the concept of the undo-key” that I had my real epiphany. What she was talking about was a kickstarter project called Robot Turtles, a board game created by Dan Shapiro of Google that teaches primary school kids the basics of programming. While the concept is awesome, it struck me that the ability to easily undo a mistake so fundamental to Agile software development, that it is one of the first concepts you would teach. It was also the reason why infrastructure agility was something that was talked about far more than it was done. People can’t take the same risks with their data infrastructure that you can with software development, or a word processing document, and the reason is that for almost all of us, there is no genuinely effective equivalent of Control-Z for our infrastructure.
Imagine that, in order to roll back a mistake in a word processing document, that first you had to
- Open up a brand new document
- Copy all the text from the first document and past it into the second document, one paragraph at a time
- Run an macro that read the formatting on the first document
- Paste the results of that macro into the second document
Then if you made a mistake that you had to
- Delete your entire paragraph that had the mistake
- Copy the paragraph from the second document
- Find the portion of the script that had the formatting for the document you just copied back
- Run that portion of the script on the original document, and hope that it doesn’t affect any of the other paragraphs or muck up the indexing or cross referencing
Furthermore, imagine that your copy was usually twelve hours old, and you could only recover your data after you’d received permission via a formal change request that had to be approved by three managers who checked them into the change control systems, then arranged for them to be sent back, buried in soft peat for three years and then finally recycled as firelighters.
Clearly, nobody would use any software program that had those limitations, and yet that’s exactly the kind of thing infrastructure professionals have to deal with on a daily basis. It’s no wonder that their perception of risk management and that of the rest of the business are so different.
Agile methodologies deals with risk in a completely different way, it requires that you build your progress on small iterative steps, and that at the end of each step you gain some insight, which you then turn into action. Continuous testing, and continuous deployment significantly reduce the risks of major project failures previously associated with waterfall methodologies. Even with an entire data-center built on software defined infrastructure, without an easy way of testing new infrastructure builds, and fixing and correcting mistakes early, infrastructure operations will never be able to fully support the kinds of agility the business increasingly demands from IT. So long as internal IT lacks an effective undo-key, they will be stuck in the world of waterfall methodologies, and a cost effective, agile private cloud built on software defined principals will remain a future vision instead of a present day reality.
The nice thing from my perspective is that NetApp uniquely provides a well proven set of tools that provides the fine grained undo that works from a single document on a home drive, all the way up to a petabyte scale data-center. We provide a Control-Z that lets you innovate safely, and realize the benefits of private cloud on technology that is already in production in thousands of data centers.
Future blog posts will concentrate on specific technologies like Snapmirror, SnapCreator, and NetApp Shift and how they create and enable a Universal Data Platform that can be used to eliminate the risk that stands between where virtualization stands today, and a truly agile, hybrid cloud tomorrow.
Storage– Software Defined Since 1982
if you take that 3 step process for creating a “Software Defined” infrastructure that I outlined in my previous post, you could reasonably say that storage has been “software defined” since about 1982 (arguably as early as 1958 when the first disk drive made its appearance)
e.g.
- Step 1 – identify and then formally define a set of common functions or primitives performed by existing infrastructure that are optimally run in purpose built devices (e.g. hardware filled with interfaces and ASICs) – This becomes the "Data Plane".
- From a data storage perspective I have broken down what I see as the common storage primitives into four main categories. I’ll probably use these categories as a tool for functional comparisons of various Software Defined Storage implementations going into the future.
placement managment – e.g. given an logical address and some data by a requestor, write that data to an underlying storage medium so that it can be subsequently retrieved using that address without the requestor needing to be aware of the physical characteristics of that underlying storage medium
access managment – e.g. given an address by a requestor, read data from an underlying storage medium and make it available to the requestor. Additionally in the case where multiple requestors may make simultaneous requests to place or access the same data, provide a mechanism to arbitrate that access.
copy management – e.g. given a set of source addresses and a range of target addresses, copy the data from the source to the target on behalf of the requestor
persistence management – in most storage systems this is an implied function, though increasingly with the rise of protocols such as CDMI, and XAM, data persistence SLOs are being explicitly defined at placement time. In most cases however, data must be stored until the device itself fails, and the device is generally expected to have a lifetime of multiple years.
- Step 2 – Create a protocol that manages those functions
- The great thing about standards is there’s so many of them … and the storage industry just LOVES forming standards bodies to create new protocols to manage the functions I described above. Many of them have been around for a while: SCSI was standardised in 1982, NFS in 1989, SMB in 1992 (kind of), OSD in 2004 and in more recent times we have seen implementations like XAM in 2010, and most recently CDMI which became an ISO standard in 2012.
Some of us get religious about these standards and which one should be used for what purposes, what I find interesting is that they all seem to be converging around a common set of functionality, so it’s possible that we will eventually see one storage protocol to rule them all, but I doubt it will happen any time soon. In the near term, whether we need to create another new protocol is debatable, but as of this moment I’m pretty impressed with the work being done at SNIA with CDMI, not as a “new replacement” but as something which leverages the work that’s already been done with the other protocols and fills in their gaps, but I’m getting WAY ahead of myself here.
- Step 3 – Create a standards compliant controller that runs on general purpose hardware (e.g. an intel server, virtualised or otherwise) that takes higher order service requests from applications and translates those into the primitives codified in step 1, over the protocol devised in step 2. – This becomes the "Control Plane"
- Well if you accept that the existing storage protocol standards are functionally equivalent to the OpenFlow Protocol in Software defined Networking, then pretty much any modern operating system could function as a controller. Also any modern hypervisor also acts as a controllers, and any storage array which uses SCSI protocols to talk to the disks at the back end also acts as a controller, and in my view this is an accurate description.
- Each of these constructs acts a a standards compliant controller in a software defined storage infrastructure, with multiple levels of encapsulation with consequent challenges that there is significant functional control overlap between these controllers. Over the next few posts I’ll go through what this encapsulation looks like, where the challenges and opportunities are in each level, the design choices we face, and build that up so we can see how close we are to achieving something that matches some of they hype around software defined storage.
It’s also worth noting that until I’ve reached my conclusion, much of what I’ve written and will write will not neatly match up with the analyst definitions of software defined storage. If you bear with me we’ll get there, and probably then some. My hope is that if you follow this journey you’ll be in a better position to take advantage of something that I’ll be referring to as “SLO Defined” storage (simply because I really don’t think that “Software Defined” is particularly useful as a label)
If you want to jump there now and get the analysts views, check out what IDC and Gartner have to say. For example IDC’s definitions of software defined storage from http://www.idc.com/getdoc.jsp?containerId=prUS24068713 says in part
software-based storage stacks should offer a full suite of storage services and federation between the underlying persistent data placement resources to enable data mobility of its tenants between these resources
The Gartner definition which isn’t public, takes a slightly different approach and can be found in their document “2013 Planning Guide: Data Center, Infrastructure, Operations, Private Cloud and Desktop Transformation” where it talks about higher level functionality including the ability for upper level applications to define what storage objects they need with pre-defned SLO’s and then have that automatically provisioned to them. (or at least that is my take after a quick read of the document).
IMHO, both of these definitions have merit, and both go way beyond merely running array software in a VSA, or bundling software management functions into a hypervisor, or pretty much anything else that seems to pass for Software Defined Storage today, which is why I think it’s worth writing about …. In …. Painful …. Detail ![]()
As always, Comments and Criticisms are welcome.
John
Software Defined .. Why Now ? Why Bother ? …
Monday is my admin clean-up and research day, which makes it the best day for quadrant-II thinking, and most of what I’ve been thinking about recently is software defined storage, or if you’re an Openstack advocate then you’d call it software-led storage.
After spending more than a few weeks thinking and researching, I’ve come to the conclusion that I’m not a big fan of either term, especially as it pertains to storage. Given the likelihood of an increasingly fuzzy set of layers between hardware and software, I think that “software-led” is probably a more useful way of talking about the future of storage infrastructure, but even so I’m still not convinced it’s the most useful description either. Nonetheless, for the moment a lot of people are talking abut software-defined networks, datacenters and storage, so I’ll start to outline my breakdown of storage within that paradigm.
Software defined anything has its roots in software defined networking and OpenFlow, so the rest of this post goes through how I see Software Defined Networking, and then I’ll use that as a framework in future posts for talking about software defined storage.
So how do you define “Software Defined” I think if you’re going to use the term without it being just another way of saying virtualised, then you need to be talking about infrastructure built on the principal of a clean separation of hardware optmised functions from software control structures, or , in the parlance of Software Defined Networking separating the data plane from the control plane. That means to create something that is truly Software Defined XXXX and not just a marketing-sexy-me-too-rebrand you have to
- identify and then formally define a set of common functions or primitives performed by existing infrastructure that are optimally run in purpose built devices (e.g. hardware filled with interfaces and ASICs) – This becomes the “Data Plane”
- Create a protocol that manages those functions
- Create a standards compliant controller that runs on general purpose hardware (e.g. an intel server, virtualised or otherwise) that takes higher order service requests from applications and translates those into the primitives codified in step 1, over the protocol devised in step 2. – This becomes the “Control Plane”
The prime example of this is with software defined networking world that could be something that looks like this …
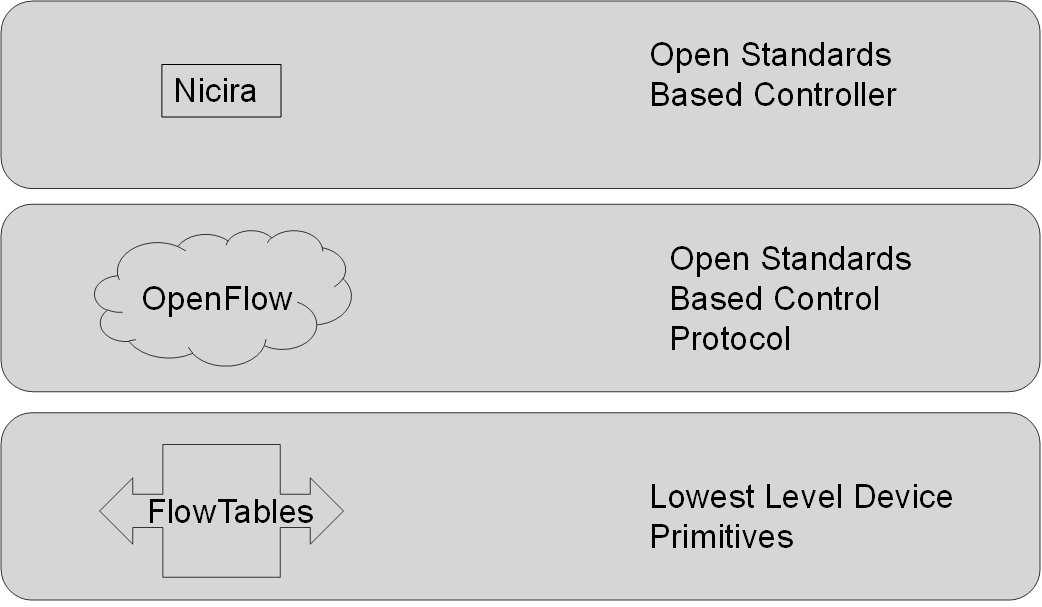
So why did this happen in networking, and not storage or compute ? Why now ? And why bother ?
As to why it happened in networking, there are a half a bazillion blogs out there on the subject, of which I’ve only read a small fraction, but from my perspective, I reckon it happened because of the following reasons
- by its very nature, customers have demanded that networking vendors must inter-operate with other vendors equipment in as seamless a fashion as possible
- there has been one absolutely dominant player in the market at pretty much all times along with a very well supported standards body.
- Networking subsequently evolved to the point where there is one dominant layer-2 implementation (Ethernet) with one dominant layer-3 implementation (IP), and a fairly small number of upper level protocols above that (TCP/UDP/HTTP etc).
- This has driven the similarity of network equipment functionality from disparate vendors that allowed the developers of openflow the opportunity to identify the commonality of flow-tables in hardware on which the elegant separation of control and data planes in SDN is built.
Like many “new and revolutionary ideas”, it probably worth noting, that this revolutionary “new” architecture has been evolving since at least 2001 when the IETF started the “Forwarding and Control Element Separation” (ForCES) working group”, and arguably before than back to 1996 with things like General Switch Management Protocol (GSMP).
But even if you can do this clean separation, why bother ? The development of openflow wasn’t driven by market requirements, it was developed to let researchers run interesting experiments on existing large scale university campus networks. While that’s a very cool thing to do as a researcher, running “experiments” on a large scale enterprise infrastructure isn’t something I’ve ever had much success with. About as adventurous as I get is asking for a vlan that spans two datacentres, and for the most part whenever I’ve suggested stuff like that in the past, I get one of those “Put the network diagram down … and STEP AWAY” looks from the network guys. I can only imagine what would happen if I said “Hey I’ve got this really cool idea for encapsulating fibre channel over token ring and running it on your existing Ethernet infrastructure”. Which begs the question, why on earth would anyone in Enterprise-IT implement want to implement something this radical ?
The answer for the most part is .. they don’t. Sure there is a promise that opening up the infrastructure will lead to more competition and that will reduce prices, but the last time I looked, the networking industry was already pretty competitive. Even of you were to pull a datacentre class switch apart into cheap basic hardware and smart software running on an Intel-box, the value that vendors like Cisco bring in terms of scalability, quality assurance, interoperability testing, support, professional services etc, will mean that in all likelihood, customers will be willing to pay a premium for their solutions, and Cisco and others like them may become even more profitable as a result. As a parallel case, there are plenty of free database offerings out there, and yet Oracle is doing just fine. You might expect that if “Software Defined” was something everyone now uses as a prime buying criteria you might see Larry Ellison extolling the virtues of a “Software Defined Database”. OK, maybe not given his rather sceptical comments about cloud in the early days, but they’re going in exactly the opposite direction, increasingly embedding more of their software into vertically integrated hardware solutions precisely because there is continued ongoing demand from enterprise customers for tightly integrated hardware/software solutions.
So if SDN isnt likely to significantly reduce costs, and there isnt an organic pent up demand within the enterprise, then where is the payoff for the large risks that come with developing and deploying any new technology ?
The answer to that question lies in the standardisation and maturity of today’s network protocols that led to the commonality expressed in flow-tables. The core protocols of TCP/IP were developed almost forty years ago and were built not only on a set of solid principals that have stood the test of time, but also on what were in 1973, some very reasonable assumptions. Unfortunately some of those assumptions no longer hold true e.g. there was an assumption that a machine with an IP address wont magically teleport from one physical location to another, yet this is exactly what happens when you try to migrate a virtual machine from one datacenter to the next. It is exactly those kinds of assumptions that are now causing problems the largest consumers of Network equipment: the large-scale cloud and telecom service providers.
That is why Software Defined Networking is suddenly interesting. For many businesses, IT infrastructure isn’t a competitive differentiator (it could be, and it should be, but right now it isn’t), but there are some very large customers, with some very large IT budgets for whom IT infrastructure is a core enabler of their business, and are willing to take on the risk of a new approach in the promise of disruptive innovation. These people aren’t just dreamers with fists full of VC dollars, but some of the networking industries largest and most influential customers. Other agile enterprise customers who understand how to leverage IT infrastructure for competitive advantage will also benefit from the investments of these larger organisations, but for the most enterprise customers, what passes today for software defined Networking will be restricted to virtual switches inside their virtual server infrastructure, and that, while useful, doesn’t exactly fit the definition I used at the beginning of this post.
Which brings me to storage .. For a number of vendors, a Virtual Storage Array = Software Defined storage, and while that’s reasonably valid, I also think it’s a bit of a half measure. I’m not saying that because I don’t like VSA’s, I do, I think they’re great, but, I don’t think that they’re the best example of what a software defined storage infrastructure can do. They might be part of it, but they’re not a necessary part, and in some cases, I’d argue that they’re not even a desirable part of a cleanly separated software defined infrastructure. And that is what I’m going to cover in my next post.
Is VSA the future of Software Defined Storage? (In reply to DuncanYB)
I was reading a blog post by Duncan Epping here http://www.yellow-bricks.com/2013/04/24/re-is-vsa-the-future-of-software-defined-storage-openi/ around VSA’s and software defined storage, and put in one of my usually overly long replies when I thought it might make a reasonable blog post here, because it outlines a number of my key thoughts on this which I was planning on writing about later on. If you get the chance, read Duncan’s post as theres some good stuff in the main blog as well as some interesting comments.
The following was my reply with some typo cleanup …
IMHO VSA’s will be an important part of the software defined storage (SDS) landscape but by no means are they the complete story. What is lacking in SDS is the equivalent of flow-tables in switches. If you go with the whole “separate the control plane from the data plane” definition of software defined anything, then you could reasonably argue that this is exactly what things like the VERITAS volume manager and file system did way back in the 80’s. For a whole stack of good reasons people chose to bifurcate that responsibility of managing that functionality increasingly into the storage and application layers, leaving those product with increasingly niche roles. The advent of SDS might change swing that pendulum back towards 80’s style architecture for a while, but people tend towards vertically integrated solutions when the complexities of managing and integrating solutions themselves becomes economically unviable, and designing a reliable storage solution with high performance at large scale that caters for a large variety or workload types is very very hard to do well.
Going back to the lack of a storage equivalent of flow-tables, the trouble with SDS is that storage requirements are much less homogenous than switching requirements and much harder to bring down to a small number of discrete functions that can be acclerated in hardware. I think that over time these will become more obvious, the first and most obvious of which is copy offload/management, but these requirements will probably evolve over time.
Rather than focus on building an industry/standards defined theoretical model, and trying to wedge/judge all the designs by that model, I think we’d be better served by loosening up the vertical integration of storage systems and then finding a variety of creative ways of leveraging large amounts of cheap CPU/Memory/Cache/Disk sitting in the virtualisation layer. VSA’s are a fairly coarse grained way of achieving this, but many of them don’t elegantly leverage tightly/vertically integrated infrastructure to accelerate or drive efficiencies where that is appropriate.
For example, there are ways of using the hypervisor resources as a “data plane” and leaving the control plane in the centralised array, such as NetApp FlashAccel . This is kind of counter-intuitive to the existing “control-plane lives in the hypervisor” model as the cache is seen as an extension of the hardware array rather than the array being seen as an extension of the hypervisor. To be fair the model isn’t that pure, as control portions are distributed between the array and they hypervisor. My point is that the boundaries become a lot fuzzier, and will be functionality will be divided and combined in a variety of interesting ways, and so long as storage is asked to perform so many different tasks, I think that’s a good thing.
While I love VSAs as a conceptually neat little package of functionality with tightly defined boundaries, (The DataONTAP VSA’s in particular, especially if you’re aware of their roadmap) I think that data and storage management will for the foreseeable future be a shared responsibility between applications, hypervisors, operating systems and arrays. The biggest challenge we face is co-ordinating these responsibilities and choosing the most efficient and automatable ways of combining them to give customers what they need without needlessly locking them into inflexible architecture choices.
Regards
John Martin
A Rant about Ethernet Based Storage Networks
There have been some really interesting discussions within the NetApp technical community around the benefits of NFS vs Fibre Channel for Oracle and VMware workloads, much of which I’m planning on plagiarizing and passing off as my own work on this blog, but in the interests of trying to keep the small shreds of integrity I have left intact, I thought I’d post up my contribution to the conversation first, because a friend of mine suggested the issues raised in the rant would make a good blog post
This response came after a series of posts on whether you needed to put in a dedicated ethernet network to carry the storage traffic, which would tend to diminish much of the “Ethernet Infrastructure is Cheaper” argument, or whether you can simply carve out a VLAN instead, what we considered to be best practice, and whether that matches what happens in a FlexPod.
My Response (slightly edited where you see the [ …] but still including the rant meta-tags that I feel should be made an official part of HTML 6) follows
<rant>
[You can just use] a VLAN, but you’d want to make sure the underlying Ethernet network was designed with storage style SLO’s eg. Not oversubscribed, no single points of failure, non-disruptively upgradable, port channels set up correctly, Jumbo frames set up correctly etc.
Using Ethernet networks designed for typical “user LAN” SLO’s and expectations for a storage network will probably screw up something at some time and is IMHO the reason why iSCSI and NFS still gets a bad reputation.
There are a number of people out there in customer network teams [….] that think they know how to design a reliable high performance Ethernet network with storage level SLO’s and many of those people overestimate their capabilities. For that reason storage teams have rightfully been wary of the network team and use FC infrastructure as an excuse to keep them from fiddling about in stuff they don’t really understand. Ethernet based storage networks make that much harder to do, but running up a brand new network design/implementation specifically for storage is still a reasonably good idea unless there is a good reason to believe the existing network has been designed with storage class SLOs in mind.
That is partly the reason why in a FlexPod, the only thing you don’t flex is the network configuration. In a FlexPod you can safely carve out a VLAN, apply the appropriate COS to it (as specified in the design guide) and be confident that you’re going to get a good result, there’s almost 40Gbit of bandwidth available in the current design, so it’s pretty unlikely you’re going to run out of that resource in a hurry, and if you do … buy another FlexPod.
Personally I’m a strong believer in multi-purpose Ethernet based networks based on 10Gbit/40Gbit with storage class SLO’s. The economic benefits go way beyond just reducing the costs of FC infrastructure and goes to the principal of large pools of [stateless] physical resources [from which virtual constructs are] provisioned automagically on demand, and this ties in really nicely with [NetApp’s] overall value proposition. Cisco, not surprisingly have a pretty good pitch around this, and [it would be worth working with them on this]. Furthermore, it also allows you to get involved in the ever increasingly sexy subject of software defined networking.
Transformation of the network infrastructure gets LOTS of attention at the C-Level and providing solid justifications / use cases for that can help [the customer accelerate their justifications for a datacenter transformation projects].
Because of that I would never be shy about pushing NFS (or going forward SMB3) on Ethernet as a superior solution to FC, especially with things like RoCEE on the horizon as it might just be the thing that disrupt [legacy methods] as it has done in some of NetApp’s largest accounts many times over.
For me supporting FC (or even iSCSI) is more about helping a customer to protect the investment they’ve already made in legacy infrastructure while they migrate to something more efficient and flexible.
Finally this is less about NFS vs FC than it is about FlexVols vs LUNS, and LUNs are really DUMB storage containers … don’t encourage people to keep using them when they have a better alternative
</rant>
I’d be interested on any perspectives or particular interests, because I’m digging through some of our internal and customer facing documents to summarise exactly what the benefits are, where the limits are, and what you need to do to implement an ethernet network with storage class SLOs at small and large scales.
Regards
John Martin
Software Defined Networking – The Next Frontier
The following part of the post came from content I wrote for Evolve a newsletter we publish out of ANZ. It’s a a little long and technical for an executive focused newsletter, which is partly why it gets a little bit rushed in the end. What I’d like to do is to expand a little more on what I believe are the choices that can be made when separating the control and data planes in a software defined storage architecture, where the industry, and in-particular NetApp is today, where things are likely to go, and most importantly how to get value from this architectural shift.
Introduction
CIOs face the constant challenge of turning rapid technological developments into business advantage. If this was not difficult enough, there are often times when multiple technologies are simultaneously released into the market, changing the IT landscape. The datacentre is currently on the cusp of such a revolution.
As it was for workforce mobility and cloud computing, it is the network that will be at the centre of these transformations. A network connects resources to intelligence and allows us to redefine what a datacenter is, and how we consume its properties.
It isn’t just incredible speed and massive bandwidth that is causing this transformation, but the fruition of an idea that’s been in development for the last decade, and that idea is Software-Defined Networking or SDN.
Software Defined Networking
This disruptive trend in the networking industry rediscovers the old idea of separating the control and data planes in network equipment. In other words, SDN liberates the higher-level network management functions from their ties to individual boxes and instead offers the vision of a “network operating system”. This allows networked applications to provision and control their networking needs using high-level open programming interfaces provided by an SDN “network controller”. The promise of this approach has meant that in a few short years, Software-Defined Networking has turned from a simple idea meant to enable new academic networking research into a potentially industry-changing technology trend.
The reason for this is that the network virtualization technology that is part of SDN is the missing piece that completes the vision of a software-defined datacenter, where compute, network and storage resources are elastic and dynamically adaptable. This network virtualization not only completes this vision, it raises the bar on how the different virtualized components integrate and interact in new, direct and more dynamic ways. This changes what IT will expect from their storage infrastructure.
SDN and the implications for Storage
Infrastructure managers who see the promise of a software defined datacentre are beginning to see storage as an important part of the infrastructure they desire to manage within the context of an SDN. However, this is only possible if the storage infrastructure itself can be separated between software that controls and manages data, and the infrastructure that stores, copies and retrieves that data. In short, storage needs to have its own control and data planes, working seamlessly as an extension of the SDN infrastructure that will be the core of the next generation datacentre.
Part of the reason for wanting to separate the control plane and liberate the storage control software from the hardware is that software defined storage allows offloading the computationally heavy aspects of storage management related functions like RDMA protocol handling, advanced data lifecycle management, caching and compression. The availability of large amounts of CPU power within private and public clouds opens all kinds of possibilities to both network and storage management that were simply not feasible before.
With more intelligence built into the Control-Plane, storage architects are now able to take full advantage of the other two major changes in the Data-Plane. The first, and perhaps the most interesting is the increasing affordability of solid state memory such as Flash and post-Flash technology such as PCM and STT-RAM.
Optimising Performance
Phase Change Memory (PCM) and Spin-transfer torque random-access memory (STT-RAM), have the access speeds and byte addressable characteristics of the Dynamic RAM (DRAM) used in servers today, with the added and transformational benefit of the solid state persistence of Flash. These technologies are significantly more expensive than Flash is today, but the predictions are these technologies will surpass even the cheapest forms of Flash memory within five or six years. Regardless of which technology wins, the trends are clear; within a few years the majority of a server’s storage performance requirements will be served from some form of solid state storage within the server itself. When this is combined with new network technology and software like SAP HANA, it has major implications for storage design and implementation. Imagine how your infrastructure would change if every server had terabytes of super-fast solid state memory connected together via ultra-low latency intelligent networking. The fact is that many of the reasons we implement shared storage for mission critical applications today, would simply disappear.
Optimising Capacity
The second major change is the demand to store and process massive amounts of data that increases as we are able extract more value from that data through Big Data analysis. This coincides with a dramatic reduction in the cost of storing that data. Very high density SATA drives with capacities in excess of 10TB per disk are coming, but in order to surpass some hard quantum-physics level limitations they will use new storage techniques such as shingled writes and will be built optimally to store, but never overwrite or erase data. This means the storage characteristics at the Data-Plane will be fundamentally different from those we are familiar with today. Furthermore, even with these improvements in the costs and density of magnetic disk, the economics of power consumption and datacentre real-estate means that tape is becoming attractive again for long term archival storage. Finally, the economies of scale that large cloud providers have and the availability of massive computing power they are able to place in close proximity to that data means that those cloud providers will have a compelling value proposition for storing a large proportion of an organisation’s cold data.
Regardless of where and how this data is stored, the challenges of securing and finding that data, and managing the lifecycles of this massive amount of information means traditional methods of using files, folders and directories simply won’t be viable in the long term. New access and management techniques built on-top of object based access to data such as Amazon’s S3 and the open standards based CDMI interfaces will be the management and data access protocols of choice.
Conclusion
In the end the only way to effectively combine the speed and performance of solid-state storage with the scale and price advantages of capacity optimised storage is by using a software defined storage infrastructure. It is the intelligence of the separated Control-Plane powered by commodity CPU that allows infrastructure managers and datacentre architects to take advantage of these two massive trends.
While this all talks about what will happen in the future, unlike other vendors who are only just beginning to talk about building a software defined storage infrastructure, NetApp has been planning for this future for many years now.
- Clustered Data-ONTAP was built on the principal of separating the Data-Plane and the Control-Plane and is ready to take advantage of the trends in software defined networking as they evolve and are deployed into datacentres over the next few years
- NetApp’s fully supported ONTAP-Edge software runs in a virtual machine, allowing the full power of ONTAP’s advanced data management functionality on commodity DAS, and NetApp’s V-Series controllers performs the same function at extreme scale for the largest and most mission critical environments
- NetApp has released at no cost to the customer Flash-Accel technology that allows commodity SSD’s and 3rd Party PCI based Flash cards to act as an extension of our storage cache for virtualized environments. This extends the work we have done in our separation of control and data-planes for our existing customers who have not yet moved to Clustered Data ONTAP
- NetApp has partnered with Amazon to provide private storage for AWS which allows the massive on-demand compute power to be coupled with NetApp’s storage in Amazon’s datacenters
- NetApp already provides open standards based advanced programming and automation interfaces through offerings such as NetApp Workflow Automater, the Cloud Data Management Interface, SMI-S, and continues to lead the industry in providing programmable software defined storage. These aren’t just technology tick box items, but technology that drives significant competitive advantages such to companies like ING DIRECT’s “Bank in a Box”.
These are just a few of the things we’ve already done, the foundations have already been set and what NetApp will be building and bringing to the market over the next few years will truly redefine what storage is inside the datacenter, and the value it can bring to IT and the organisations it serves
A very long reply
This blog post is essentially a very long comment reply to Darius Zheng at Oracle on his blog
https://blogs.oracle.com/si/entry/7420_spec_sfs_torches_netapp#comments
I suspect it is so long that it probably needs more formatting to be readable, so I’m posting it here too
—–BEGIN REPLY—-
Thanks for posting the reply, again, I think you’re missing my point
DZ … “Oracle has 2.5x Performance for 1/2 the cost of a Netapp”
A more accurate statement is that “The Oracle 7420 attained a benchmark result that was 2.5x better for 1/2 the _List Price_ of a NetApp 3270 array in 2011 that had significantly less hardware.
What this says is that Oracles List Price is a significantly lower than NetApp’s List Price. You could say the same thing about the difference between the price of a Hyundai i30 and an Audi A3.
Secondarily, as I pointed out in previous comments the rest of the results also says that the Oracle solution make relatively inefficient usage of CPU and Memory when compared to a NetApp system that achieves similar performance.
Yes the list price of the NetApp system is significantly higher than an equivalently performing 7420, but this is a marketing and pricing issue, not a technical one. In general I like to stick to technical merits, because pricing is a fickle thing that can be adjusted at the stroke of a pen, technology requires a lot more work to get things right.
In the end, how this list price differentiation translates into what these solutions will actually cost a customer is highly debatable. I do a LOT of research into street prices as part of my job, and in general storage is increasingly purchased as part of an overall upgrade and this is where the issues get murky very quickly as margins are moved around various components within the infrastructure to subsidise discounting in other areas. Having said that, I will let you in on something, based on the data I have, for many quarters, in terms of average $/RAW TB paid by customers in my market, Oracle customers paid about 25% MORE for V7000 storage than paid by Netapp customers for storage on FAS32xx and that only recently did Oracle begin to reach pricing parity with NetApp. We could argue the ways the analyst arrived at those figures, but from my analysis the trend is clear across almost all vendors and array families vis. The correlation between customer $/TB is strongly correlated with the implied manufacturing costs, and very poorly correlated with the vendor list prices. The main exceptions to this are new product introductions when there is a compelling new and unique value propositions (e.g. DataDomain) or when vendors buy business at very low or even negative margin in order to seed the market (e.g. XIV in the early days)
Now personally, I disagree with NetApp’s list pricing policy, however there are reasons why that list price is so much higher than the actual street price most people pay. Many of those reaons have to do with boring things like long term pricing contracts. If you’d like to turn this into a marketing discussion around pricing strategies, I’m cool with that, but I don’t think the people that read either of our blogs are overly interested. However I will say this again, the price people pay in the end, has more to do with the costs of manufacture, and a solution that gets more performance out of less hardware will generally cost the customer less, especially if the operational expenses are lower.
DZ .. “Why wouldn’t a customer want more CPU and Cache?”
Why would someone want less CPU or Cache ? … because it costs them less, either in street pricing terms, or in the cost of powering or cooling them. And yes, I believe that that a 7420 controller with more than eleven times as many CPU cores, and more than one hundred and sixty times as much DRAM will chew a lot more power and cooling than a 3270 controller.
It’s not just the cost of the electricity (carbon footprint and green ethics aside), its also the opportunity cost of using that power for something else. Data centers have finite resources for power and many (most) are very close to the point where you cant add more systems. In those environments, Power hungry systems that aren’t running business generating applications are not viewed kindly.
JM Interpretaiton of DZ … “Happy to do a power consumption comparison, where is the netapp information ?”
I’ve answered that in a simlar question to me on my blog at storagewithoutborders.com – See the blog-post URL in a previous comment re getting access to power consumption figures.
DZ .. You say the Netapp cache is SO efficient and you talk about an old non relevant 3160 SPEC SFS post
I referenced the “non relevant 3160 SPEC SFS post” because it is relevant, being the place where NetApp tested the same controller with a combination of flash acceleration, no flash acceleration, with both SATA, and FC/SAS spindles. The specific one I referenced was the most comparable configuration that includes flash and a 300GB 15K disks which as I pointed out achieved 1080 IOPS/15K Spindle with a cache that was 7.6% of the fileset size.
If you prefer I could have used the more recent (though still old) 6240 dual node config which uses 450GB 15K disks and achieved cache that achieved 662 IOPS per drive but with a cache that was a mere 4.5% of the file-set size, or the 24 Node 6240 config which achieved 875 IOPS per drive with a cache that was 7.6% of the file-set size. As you can see a modest amount of flash improves the IOPS/disk enormously, and there is a good correlation between more flash as a percentage of the working sets and better results in terms of IOPS/Disk. Before you ask, as far as I can tell, the main reason for the difference in IOPS/spindle between the 24 Nodes 6240 and the old 3160 with a similar cache size as a percentage of the fileset, is that NetApp’s scale-out benchmark used worst case paths to from the client to the data to provide a squeaky clean implementation of SPEC’s uniform access rule.
DZ .. “You fail to mention that the 3270 gets a MEASLY 281 IOPS per drive and that the 3250 gets a whopping 300 IOPS per drive. So your point is that the 3250 was done to compare with the 3270? What was the 3270 done for?”
Neither the 3270, nor the 3250 benchmarks used flashcache, so the IOPS/spindle are going to be good, but not stellar. I don’t know exactly why we didn’t use flash in the old 3270 benchmark maybe its because SPEC-SFS is a better indication of CPU and metadata handling than it is about reads and writes to disk, and like I said, we’d already proved the effectiveness of our flash based caching with the series of 3160 benchmarks.
Going in to the future, I doubt NetApp will do another primary benchmark without flash, but its worth saying again, that the 3250 was done to show performance equivalency with the 3270, so that configuration was as close to identical as NetApp could, and that meant neither the 3270 or the 3250 benchmarks used Flash to improve the IOPS/disk. If NetApp had done it, I have every reason to believe that the results would have been in line with the 3160 and 6240 benchmarks referenced above.
DZ .. “I thought the purpose of a benchmark was to compare many vendors systems against each other with the workload remaining consistent?”
NetApp tends to use benchmarks as ways of demonstrating how much a their technology has improved against a previous NetApp baseline, to help their customers make good purchasing decisions. Proving they’re better than someone else is not a primary consideration, though often that is a secondary effect. Oracle is free to use their benchmarks in any way they choose, personally I’d love to see a range of configurations from each technology bench-marked rather than just sweetspots, maybe opensfs and netmist will bring this about, but the fact is, running open, verifiable, and fairly comparable benchmarks is expensive and time consuming and I will probably never see enough good engineering data published. If you’ve got some ideas to simplify this, I’d love to work with you on this (seriously, we might compete against each other, but we both clearly care about this stuff, not many do)
DZ .. With that in mind the Oracle 7420 still crushes the netapp in price, efficiency and performance. I am guessing we are also still better or comparable in power usage as well.
You’ll see from the above that I respectfully disagree with pretty much everything in that last statement, and I’m looking forward to that controller power usage comparison 🙂
—END REPLY—

Copyright

Storage Without Borders by Richard J Martin is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
Based on a work at www.storagewithoutborders.com.
Permissions beyond the scope of this license may be available at www.storagewithoutborders.com.
